2024年11月27日,由清华大学计算社会科学与国家治理实验室主办的清华交叉学科研究能力提升计划“大数据与因果推断研讨班”第四期在线上举行。浙江大学经济学院张川川老师应邀作为主讲人,做了主旨为“行政数据及其在医疗问题研究中的应用”的讲座。讲座全程由清华大学公共管理学院陈思丞副教授主持。
本次课程分为三个部分:第一部分介绍什么是行政数据,第二部分介绍当前在医疗政策方面的主要研究议题,第三部分是目前国内的学者使用行政数据研究医疗问题的一些案例。
首先,张川川老师从社会科学经验研究的流程开始,提到基于经验检验的应用研究的分析范式,进而引入检验研究的核心要素之一:数据。

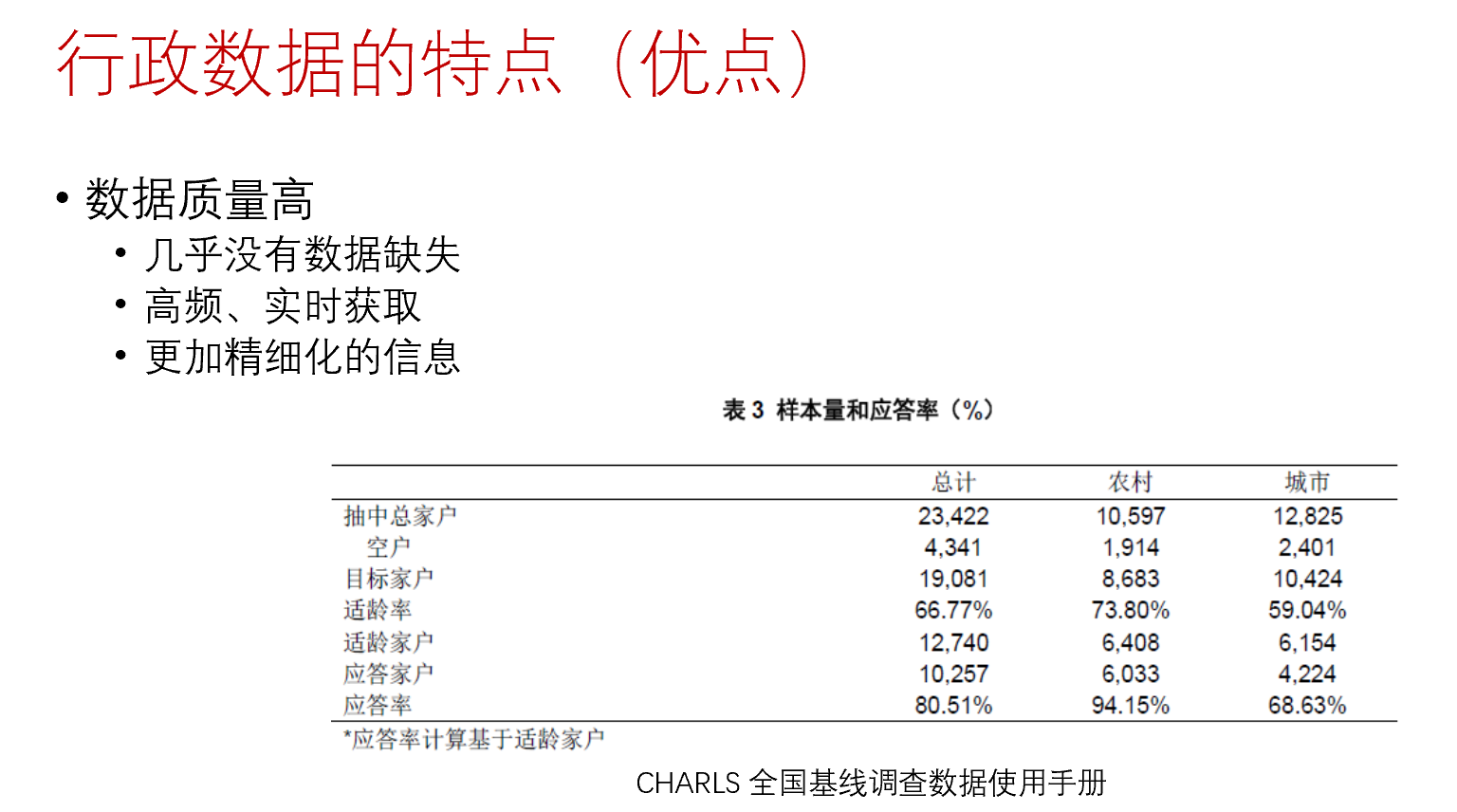
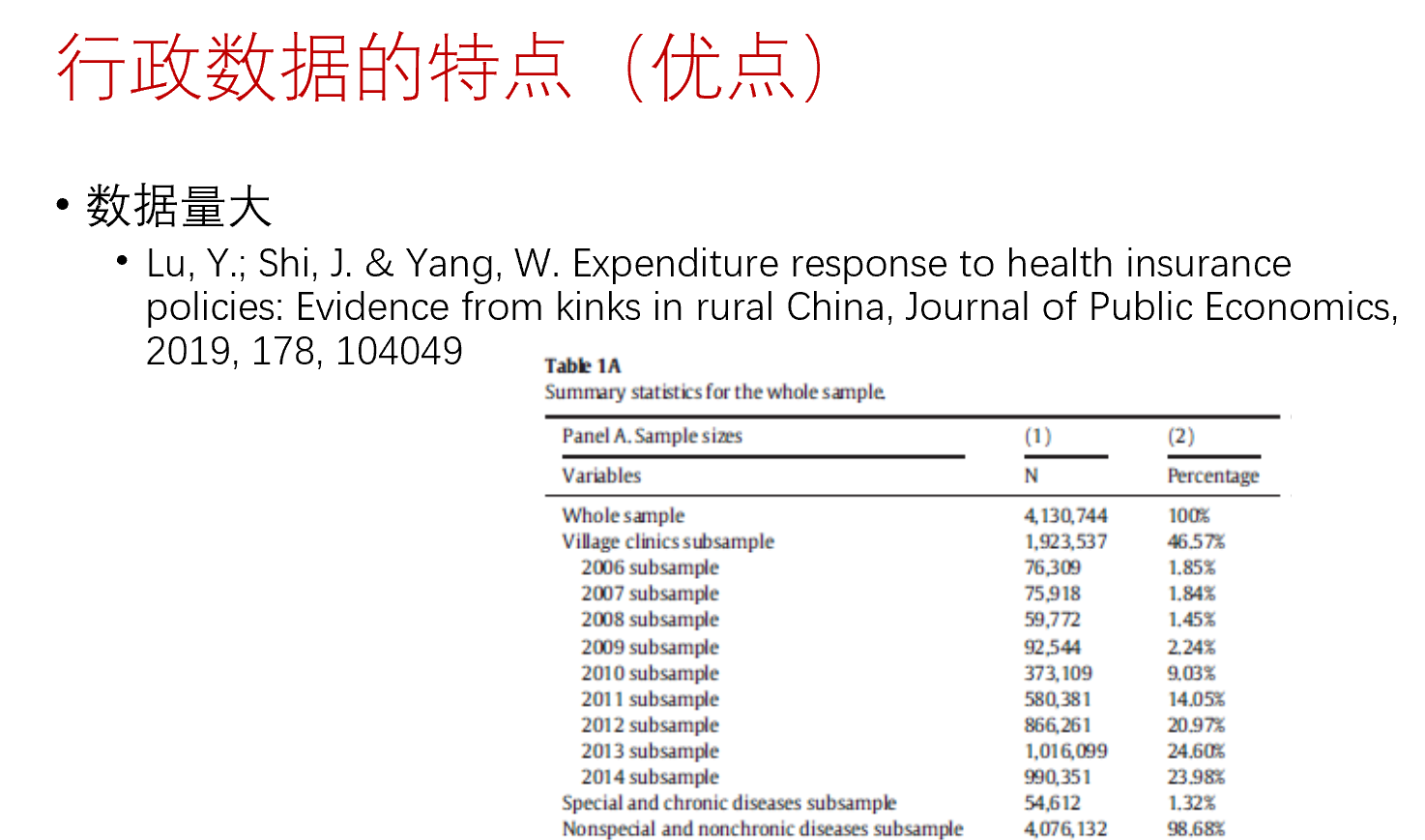
从经验研究的现状来看,常见的数据类型有三种。第一种为统计数据。这些统计数据是由政府还有一些研究机构对原始数据进行加工处理之后生成的。常见的统计数据有国家统计局发布的中国统计年鉴、城市统计年鉴、教育统计年鉴;还有其他各部门,如卫建委、农村农业部、工信部等等发布的数据;也包括如WHO、World Bank等等国际机构发布的数据。这类数据的结构非常的简单,变量少,观测值少,因此样本变异小,能揭示的信息有限。第二类为微观调查数据,如CHIPS、CFPS、CHARLS等等,这些微观数据的变量多、样本量大、颗粒度小,因此在分析企业或者家户的行为比较有优势。第三种为行政数据,指政府或者其他组织收集的不以统计为目而自动生成的数据,这类数据在近十几年来经济学领域出现的频率越来越高。行政数据具备非常多优点:首先,其数据量极大;其次其数据质量高;再者是其总体全覆盖、便于追踪,同时对学术研究而言数据收集成本低(由于数据已经存在)。

接着,张老师强调了利用详尽的行政数据对于解决复杂医疗问题的重要性,并提到了世界卫生组织设定的三大医疗保障体系目标:改善人们的健康状况、确保医疗服务的资金支持以及满足公众对健康的期望。

面对医疗领域内的资源分配难题和信息不对称带来的挑战,张老师详细解释了当前医疗政策面临的多重困境,包括如何在提高健康资本的同时控制成本,以及如何处理医患之间由于专业知识差距导致的信息不对称问题。此外,他还讨论了构建一个高效且公平的医疗服务体系所必需克服的障碍,特别是涉及患者、医保机构、医院及医药企业等多方利益相关者之间的协调问题。

随后,张老师分享了当前医疗政策关注的一些热点话题,比如通过财政手段加强对医院预算的控制,推动分级诊疗制度以缓解大型医疗机构的压力,以及探索在线诊疗等新型服务模式。同时,他也强调了调整报销比例和改革支付方式对于优化资源配置的重要性。


张老师呼吁加强基于实际经济数据的量化评估方法的应用,采用因果推断技术来科学地设计和改进医疗政策。他指出,在中国医疗体制改革的过程中,找到政府干预与市场机制间的平衡点至关重要,这不仅关乎有为政府和有效市场的实现,也是促进整个社会福利提升的关键所在。
接下来,张老师详细分析了当前医疗政策研究的中国问题。结合学术研究的本土化、规范化和国际化,阐述了人口老龄化背景下中国的医疗政策主要面临医疗支出快速增长、医保的二元体系和医疗资源使用效率等挑战,并根据医保、医疗和医药的政策文件为学员们提供了选题思路。
然后,张老师系统梳理了健康经济学和医疗保障领域的经典文献。从医疗保障供给和需求两方面对已有文献进行了介绍,总结出相关研究主要集中在社会经济因素如何影响人们的医疗服务需求,以及经济激励如何影响医院、医护人员和医药企业行为两个方面,并为学员们总结了健康经济学的研究议题。
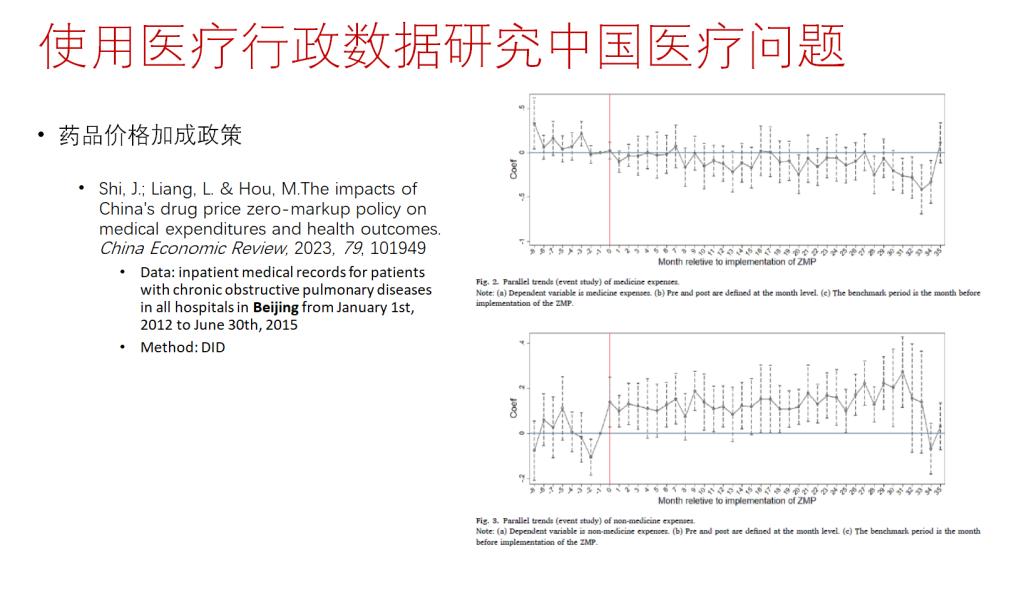
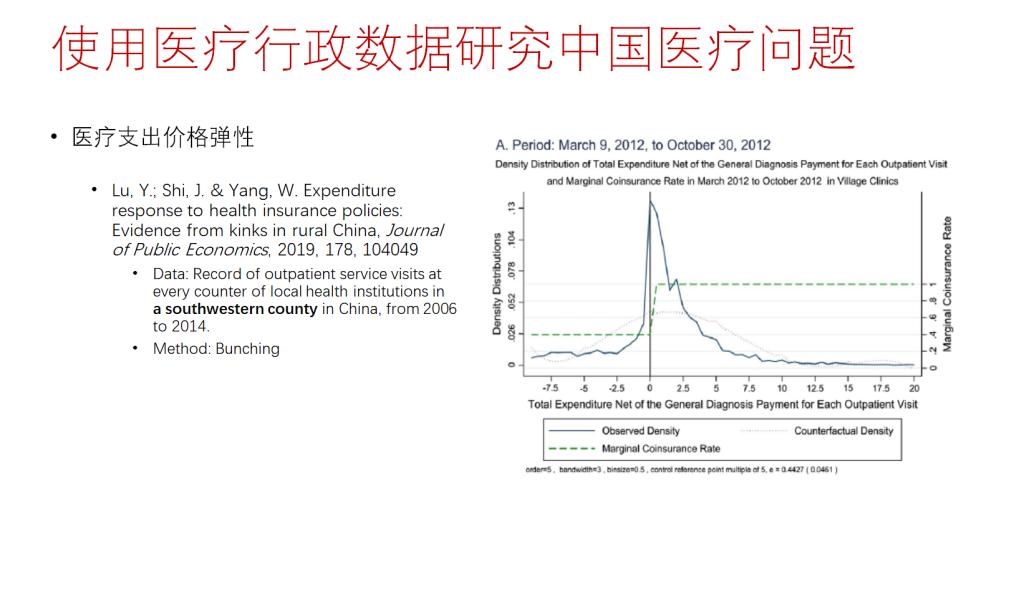
接着,张老师讲述了使用医疗行政数据进行学术研究的相关案例。一是张老师团队采用DID方法对公立医院的医药分开改革进行政策评估,Shi et al.(2023)使用北京市2012-2015年所有医院某一类疾病就诊记录数据也进行了类似的研究。二是Lu et al.(2019)采用Bunching的方法,使用中国西南某县门诊数据研究了挂号费调整对患者医疗支出的影响;三是Feng et al.(2020)采用DID+RD的方法,使用上海市和成都市医保的行政数据研究了医保待遇调整对医疗服务利用和医疗支出的影响;四是Zhou et al.(2021)使用成都市医疗行政数据研究了医院扩张对医疗支出的影响。张老师提到近年来使用医疗行政数据的研究开始频现,数据实验效果和发表质量较高,成为未来研究的一大趋势。
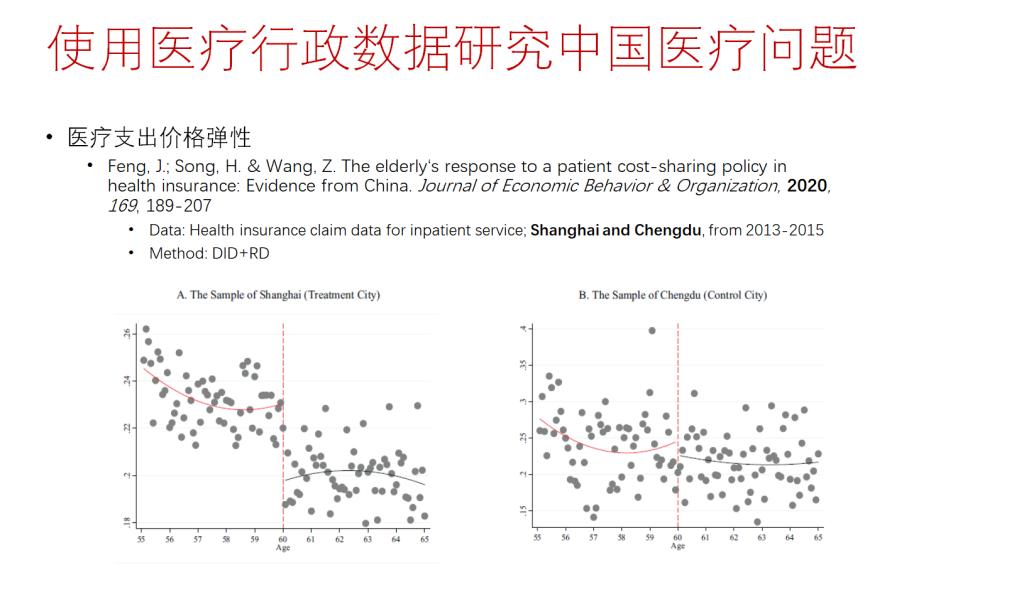
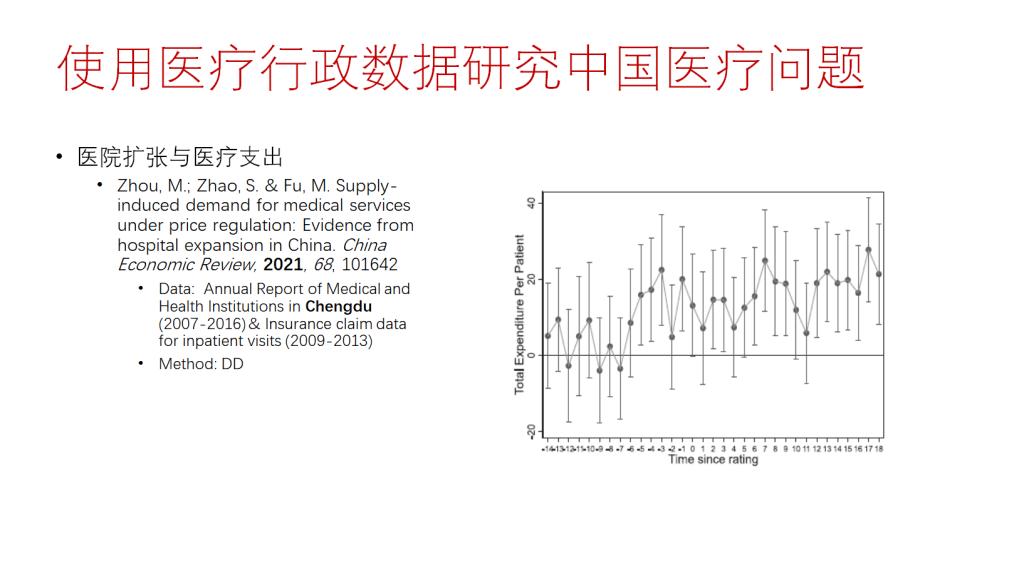
最后,张老师总结了使用行政数据面临的前景与挑战。当前,行政数据使用主要面临机构与研究人员之间缺乏联系、缺乏数据分享使用的制度以及研究人员对数据隐私的保护不足等问题。张老师从制度建设和行政数据获取方面给出了相关建议,提高了学员们利用行政数据开展学术研究的热情。
撰稿人
北京大学 博士生 叶濯缨
中国人民大学 博士生 汤 佳
南京农业大学 博士生 苗哲瑜


