2024年7月3日,2024中国数字经济发展和治理学术年会在清华大学成功举办。本届学术年会聚焦“数据要素、人工智能与数智时代的理论创新”,邀请国内外40余位专家、学者及机构代表进行主旨演讲和交流。来自清华大学、北京大学、中国人民大学、中国科学院大学、中国社会科学院大学、浙江大学、南开大学、上海交通大学、西安交通大学等高校和数字经济相关科研机构及企业代表共400余人出席线下会议。会议通过多个平台同步直播,当天信息浏览量超过十万人次。
康奈尔大学约翰逊商学院讲习讲授、金融科技中心主任、NBER研究学者丛林以《关于金融人工智能的思考和可解读的不太大模型》为题进行了主旨演讲。本人根据丛林教授现场发言内容整理。

丛林教授作主旨演讲
大家好,很荣幸能再次来到现场参加这个大会!
今天的主题主要是讲关于金融人工智能的一些思考,题目是“不太大模型”,我从去年起就在提一些跟主流思想不太一样的一些观点,这次复述一下,供大家参考。我的发言也是基于三篇论文。自2018年起我们就在探索金融方面的人工智能模型,这三篇(论文)跟今天主题更相关一些。

首先,人工智能里有“智能”,我们为什么把它叫做“智能”呢?很多时候是跟人的智慧联系起来的。斯坦福人工智能中心的定义提及人工智能是可以学习一些方法,并且使用这些方法,解决一些复杂的问题,来达到一些目的,当然是在很复杂的环境里。这里的重点是目的目标导向。
什么是AI?如果我们去定义,它跟自动化是不同的。自动化有时也很复杂,比人做一些事情效率高很多,但是为什么没有把它叫做“智能”?主要的原因是我们自动化的时候,很多时候还是以指示引导,人工智能很多时候是以目标为引导,你可以告诉我一个要实现的目标,比如经济的目标,比如说我要做财富管理,我要保证我不能损失掉50%的财富,同时我要最大化我的回报率,这就是我的一个目标。我给你这样一个复杂的目标,在一个复杂的环境里面,如果机器能在较少的指令下很好地给我们一个解决方案,它就显示出来很智能。
我认为人工智能现在发展基本上有三个大方向。一部分是我们的模型会越来越大,把复杂度会扩得很大。从某种角度来讲,人工智能是把模型的空间扩得很大,并不是什么魔术。以前我们用的模型可能小一些,人工智能就是一类大的模型,模型的空间更大,所以才能捕获更多的信息。之前大模型很多时候是往横向的方向发展,需要更多的运算,需要更通用。大家现在看到越来越多的大模型趋势已经很明显。这是其中一个发展方向,在金融的应用可以更垂直。我们不需要分析师同时也是很有创意的画家。
第二个方向,一旦模型的空间扩得很大,就需要更多的数据,去寻找更多的数据来训练模型是很重要的发展方向。对金融来说,我们的数据量比起自然语言或者图像数据量并不是太大,要找到更多的数据并不是容易找到。计算机领域或者AI领域提出的一个解决方案就是可以从其它的场景、其它的数据学习一些信息,然后再回到我们要解决的问题上,用我们有限的数据再去训练模型,牵扯到迁移学习或者是transfer learning或者是预训练pre—training,我们现在看到的很多大语言模型基本上都是这么做的。训练的模型并不是要解决具体任务相关的数据。这是第二个方向,但金融领域里的数据并没有那么多。所以要么拓展数据,要么探索迁移和与训练,其实还有一种办法是把逻辑和知识跟当下数据驱动的方法结合。
第三是优化搜索算法。既然我们把模型空间扩得很大,比如说以前的AlphaGo包括现在的ChatGPT,在这么大的模型空间里要想完成地优化目前的算力远远不够,是做不到的,你就要想办法用一个比较聪明的方法,在这个大的模型空间里找到一个很好的解决方案。计算机领域包括AlphaGo、Self-driving、现在的大语言模型,主要走的一个方向是强化学习,强化学习就是trial and error,它是一种heuristic search,是近似的dynamic programming, 是数据驱动的multi-arm bandit。在一个大的模型空间里通过跟环境互动调整,基本上能够找到一个很好的解决方案。
我等一下会提及我们推出的一系列的面板树模型,panel trees,是用另外一种搜索优化的方式。模型相对比较小,表现不比我们的大模型差,而且是非常可解读。
刚才讲的更多是从AI的角度出发,我们关注一下金融领域的应用,看一下金融的主要问题:资产的管理,包括公司金融、CEO/CFO很高维的动态的决策、资产回报的预测、资产定价。传统研究的方式其实并不是很完善,比如说我们想用一些测试的资产来验证我们的一些资产定价的理论,我们的资产怎么选?我们一般选很多股票,按照市盈率、book-to-market 、earnings growth,用这些公司的指标给它分成几组,然后做多、做空。但是我们一般做的是 Univariate-sort、 double-sort、 Triple -sort,但公司的这种指标有几十个,你为什么不去做一个更广泛的资产归类呢?五六十种的排列组合?因为计算量太大,我们做不了。其实人工智能就给我们提供很多方式来解决这样的问题。再有,我们建立金融模型,一般都是用一个通用的模型或定价系统,它应该是给所有的资产都定价,这是我们一般的方式,没有考虑它的异质性,也许有些资产模型就是给某一类资产在某种宏观环境下才有更好的定价表现,也许某些资产就是在某种宏观环境下才有更高的预测性,这些异质类的分析,人工智能也给我们提供很多帮助。目前金融机器学习的应用还没有涉及到这些问题。等一下我会举几个简单的例子,没有时间讲太具体,如果大家看一下论文,还是可以从中体会到这些问题的重要性。
最后,对金融领域人工智能的几点观察。
首先,金融人工智能模型不一定非要大,我们没有那么多数据,如果你是一个研究机构,你的运算力也拼不过OpenAI或者是公司的运算能力。同时我们并不要求它很通用,我们并不是走一个横向的扩展,我们做一个金融分析师的时候,并不需要他同时也是一个很好的画家或者是很会讲相声。我们其实更多地是要让它在垂直领域更专业,可能很多数据并不能交到一个开放式的平台上面,因为这种情况有一些隐私的问题,同时,是不是一些平台变得too-large-too-fail,它的相关性很高,会带来一些系统性风险。
我们也希望金融领域的人工智能要准确,我们并不需要它有发散思维或者特别有创造力,我们希望它给我们一个正确的答案或者是有一定的鲁棒性、稳健性,其实在医疗领域也有同样的问题,这跟通用大模型的思路其实不太一样。
最后,我们在经济领域,很多时候要强调可解读性。今天我讲的这些“不太大模型”,其实解读性就会高很多。当然还有一个更大的课题,今天没有时间讲,也不只局限于金融,就是对齐的问题,这是非常大的问题,涉及宗教、文化各个方面。
之前提到,在计算机领域或者是在人工智能领域,主流的一个方向还是用强化学习。我们也有探索。在关于Transformer,也就是ChatGPT里面的T,的文章出来不到两年时间,我们团队就做出金融学术领域第一个大模型AlphaPortfolio用于投资,之后我们又花了三四年时间做了一个AlphaManager,相当于为公司金融建一个所谓的世界模型。其实物理世界比较难去建这个模型,但是经济世界是可以建的,包括很多原理,这些东西并不是严格像牛顿定律这样严格执行。我们经济学管理学应该往这个方向尝试。但我今天讲的是另外一个方向,是关于用树的结构建不太大的可解读AI模型的思路。
为什么用树的结构呢?树的结构是一种Greedy Search,它也能够很好地达到在一个大的模型空间里找到一个很好的解决方案,而且它其实是借鉴了人的智能。为什么这么说?当我们解决一个复杂问题的时候,我们会把一个大的问题分解成很多小的问题,然后逐个击破,就是divide and conquer这种思想。《孙子兵法》里叫分而治之,各个击破。树的结构其实就是用来做这个事情,所以也符合智能的定义。这里我们更强调的是此法也能把一些逻辑、已有的知识加到模型里,同时让它相对深度神经网络模型更可解读。
为什么要强调把已有的一些知识逻辑加进来?比如我们教一个学生“万有引力定律”,可以给他看到几百万个苹果砸到人头上的图片或者视频,也许他慢慢就学会了“万有引力定律”。但是更直接的一个方法,可以告诉他有牛顿这个人,他已经告诉大家有这样一个定律。如果直接把这些逻辑和知识加进来,其实是一种捷径,目前这并不是计算机领域或者人工智能领域主推的一个方向,但其实可以借鉴。如果用计算机的语言来讲,能不能结合一些知识图谱,再加上现在的大数据、大运算的一些方式。
树还有一些其它的优势,比如算起来运算成本很低,比起深度学习,它应对高噪音的环境,效果也很好。这个很重要,因为金融市场就是噪音很大,如果金融市场signal to noise很高,有的人就用它来交易,交易着交易着就会变成噪音很大。所以,它跟工程或者是自然科学的实验室的环境还不一样。有很多原因,我们可以用树。大家如果以前用过classification regression tree的话,大家会有一些概念。
三个不太大人工智能在金融里的应用:
第一个应用,无论是在资产交易还是在资产定价里,我们很多时候做的就是资产归类。为什么做这个事情?因为要生成一些测试资产来验证你的模型或者是去做多空的投资组合。传统的做法比较随意,根据研究人员自己的知识去做。现在就有一种系统的,在大的sequential sorting、simultaneous sorting这样的一个空间里面去生成测试资产,传统的树不太适合做这种事情,因为传统的树一般假设无论是时间线还是横截面上做了一些IID的假设,这在金融市场并不成立。我们做的事情:第一,把树的模型调到可以用来处理面板的数据。第二,我们是用一个经济的指标economic goal来长这棵树。比如说我就是想造这个投资组合,它的sharp ratio最高,回报除以风险,我以这个作为标准来长我的树做资产分类,我可以做long、short的资产组合或者是做Mean-variance efficient portfolio,我最后产生的效果是好的。比如说我们做一个tree,用来资产定价,可以看到一些资产的指标,他们的interaction交互就已经解释了大部分资产的回报率里面的变化。你用它来做投资,比如说第二行右面的out-of-sample,真正把这个放到未知的数据上去看,甚至每个月换手,夏普值可以达到3左右,比很多大的深度的强化学习的模型、神经网络的模型表现得都要好。我们的参数可能不到100个,做deep learning至少需要几百万参数(比起大语言模型已经很小了),这个更小。同时你可以看到怎么样生成投资组合,你作为一个基金的管理人员,很容易去解读,你也可以很好地给你的客户讲清楚,比如说价值的指标究竟跟另外哪个资产指标做了交互,使我产生这种超额的收益?这都是可以做到的。
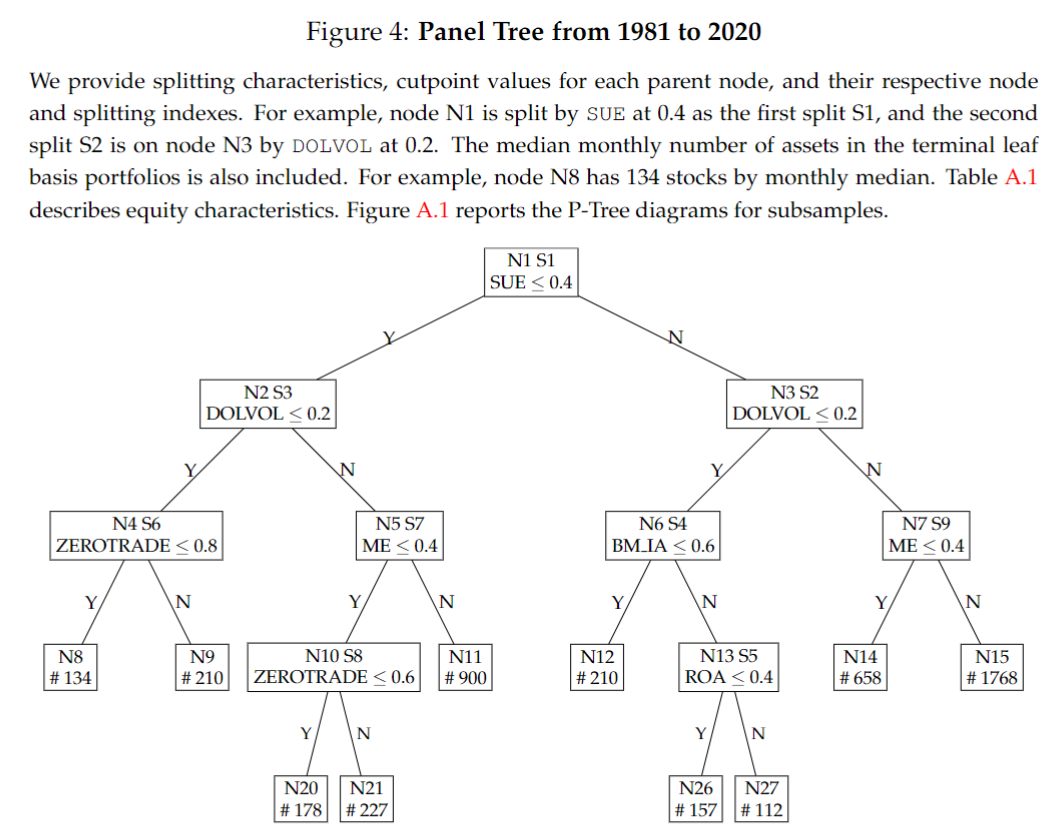
第二个应用,数据驱动分析异质群。刚刚讲的是投资测试资产,物理里面大家都在找统一的大理论。不同的理论在不同的现象中有不同的适用,量子力学(Quantum Mechanics)可能是用于小规模的世界,广义相对论是用到更大规模的世界,不同速度的世界。也许在金融领域也是这样,并不是一个模型给所有的资产做定价,是有异质性的,你怎么找这种异质性?我们做的事情是什么因子给什么资产可以定价,在什么样的宏观环境下,以前这个问题我们也有思考,中国股市的因子可能跟欧美股市的因子是不一样的,债券的因子跟股票的因子是不一样的。但这些分类基本上都是人为的,或者是根据地区性。能不能有一个数据驱动的方式来完全找到grouped heterogeneity,是可以的,把资产通过树的搜索,找到不同的资产的分组,每一个分组里的因子能够找出来,什么样的宏观环境下哪些因子更好用,还是可以找出来。比如找到市场的因子和size factor,适用于所有的资产分组。但有很多因子,可能分组之后就不是因子,它们并不是真正的定价因子,只是资产性质的一些高阶的变化产生出来的一些假象,用这个可以做很多资产定价的工作,也可以找出不同的宏观的阶段,比如说低通胀和高通胀时期,我作为一个基金经理,应该看哪些因子?这些都可以去思考。

第三个应用,用同样的框架去探究资产回报的可预测性。还是用这个树把资产分类,也许分出来一类非常可预测的资产,也有一些资回报不是很可预测。怎么做呢?回到经济指标来指导这棵树的生长。我们用了一个指标,就是预测模型究竟能解释多少数据里的变化。我把资产分类之后,我想让可预测的和不可预测的两者的差最大化,找到最可预测的一组和最不可预测的一组,用这样的经济指标,还是这个树的模型,并不是很大,你可以找到异质群。
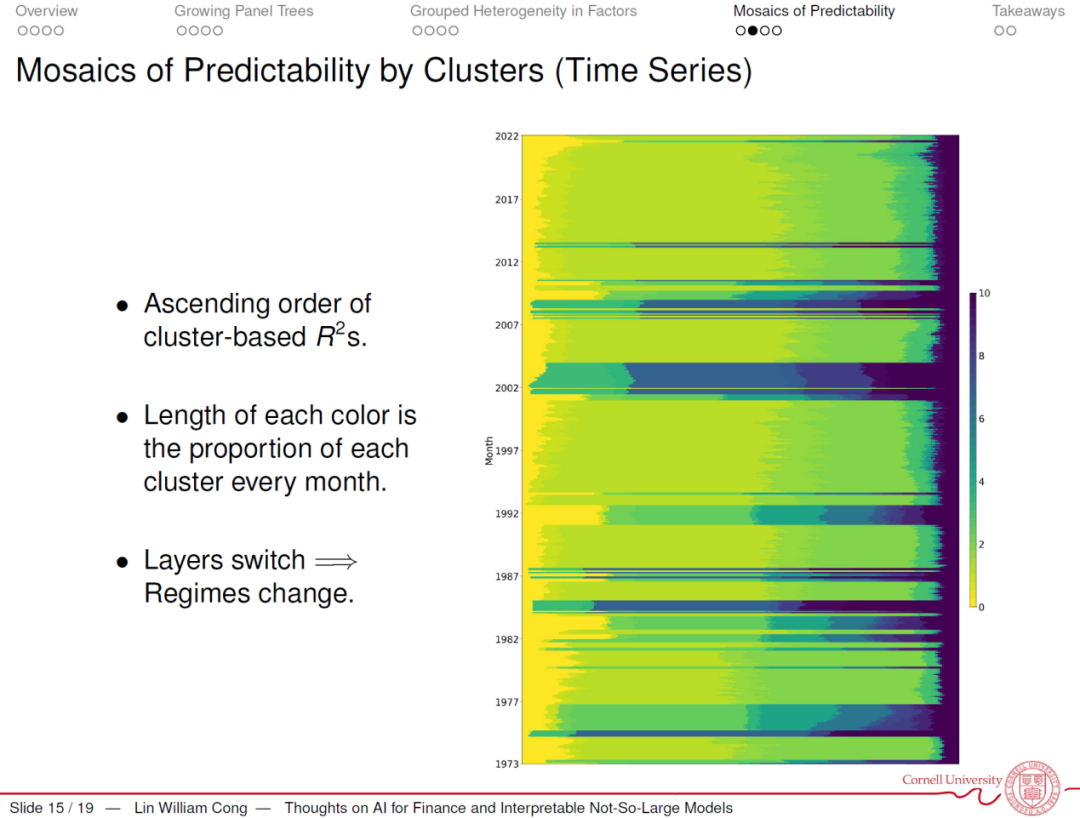
(PPT图)横轴是不同的资产,深的颜色是可预测性更高,纵轴是时间线,可以看到有宏观的大的可预测性的变化,尤其是在2000年所谓的互联网泡沫爆掉之后,或者是金融危机之后,各类资产的可预测性普遍提高了很多。用它去做预测,比如最可预测的一组,无论用什么样的模型去做预测,它比不可预测那一组有很大的差别。传统的方法并没有看这种异质性。可预测性是不是可以转化为交易的收益?我们发现的确可以转化成交易的收益。最可预测的那一组,无论是夏普值还是回报率都是最高的。
总结:
传统经济金融的核心问题,如果用一个可解读的也可运算的人工智能的方式去解决,其实是比较理想的。甚至这些方法并不局限于金融里的应用,因为在其他商业经济的场景下也是面板数据也有异质群。计算机领域或者是AI领域现在并没有往这个方向去发展,如果大家想可解读、可运算的一些不太大模型,可以考虑这样的发展方向。
具体的文章和金融科技相关的研究,也希望大家去关注我们的一些科研介绍的总结。
我的演讲就到这里,谢谢大家!


