2024年11月20日,由清华大学计算社会科学与国家治理实验室主办的清华交叉学科研究能力提升计划“大数据与因果推断研讨班”第三期在线上举办。清华大学公共管理学院张楠教授应邀作为主讲人,为2000余名在线参会者做了主旨为《基于政府网站数据的政策信息学》的讲座。张楠老师通过分享团队即将出版的学术著作成果,聚焦于政府网站为大家介绍了政策信息学的前沿方法及其应用,帮助学员在后续研究中进行高效的经验研究。
针对政府网络这个政策信息载体,张老师简要介绍了政府网站的发展历程,即政府上网阶段(1996-2005年)、内容丰富阶段(2006-2014年)、整顿规范阶段(2015-2017年)、融合提升阶段(2017年至今)。政府全国各级政府网站数据的丰富与积累为基于数据驱动的研究提供了机会,对政府网站的关注可以分类两类,一种是状态数据,另一种是内容数据,围绕政府网站绩效数据开展研究主要有两种路径,其一是以绩效数据作为因变量,其二是将绩效数据作为自变量。

紧接着,张老师回顾了政策信息学的起源和发展,指出政策信息学是面向日益复杂的公共管理与公共政策问题、基于信息通信技术与数据科学发展的解决方案,融合政策过程变革与管理模式创新的跨学科综合研究方法论。政策信息学包含三种基础研究方法:一是计算社会学,关注过程;二是社会网络分析,关注关系;三是文本挖掘与主题建模,关注内容和行为。而后张老师向学员演示了政府网站数据的应用过程,针对词语级、段落级和篇章级数据讲授了政策信息学中的内容数据采集和数据处理方法。
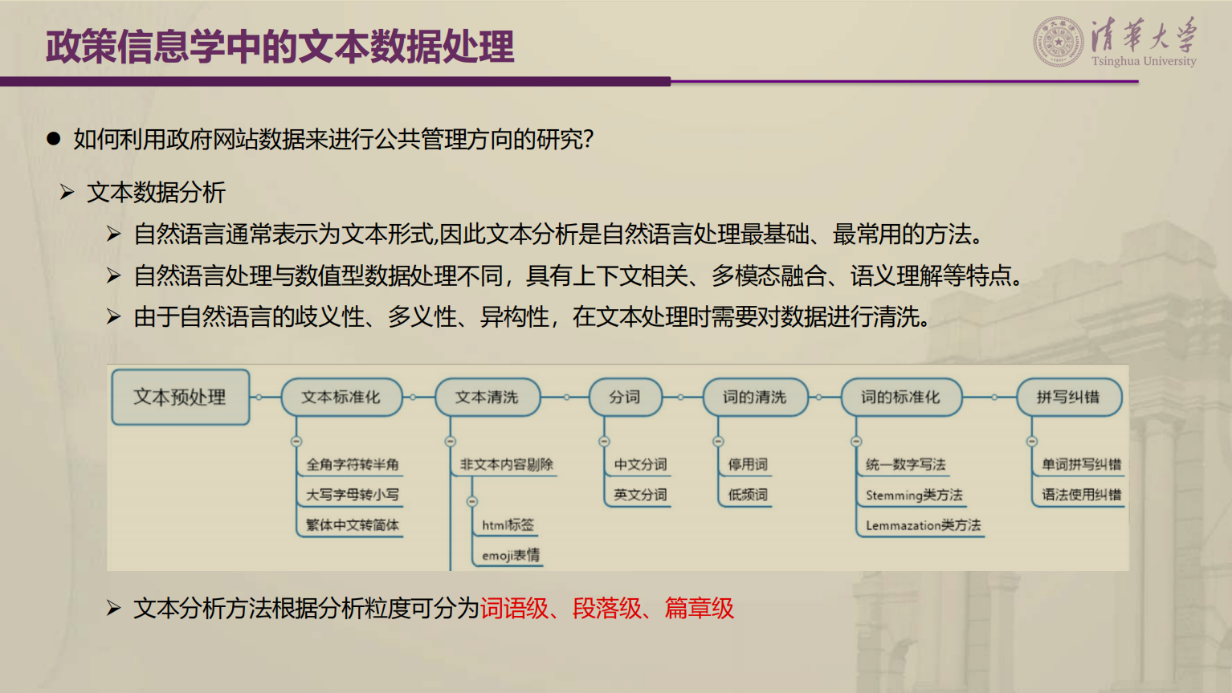
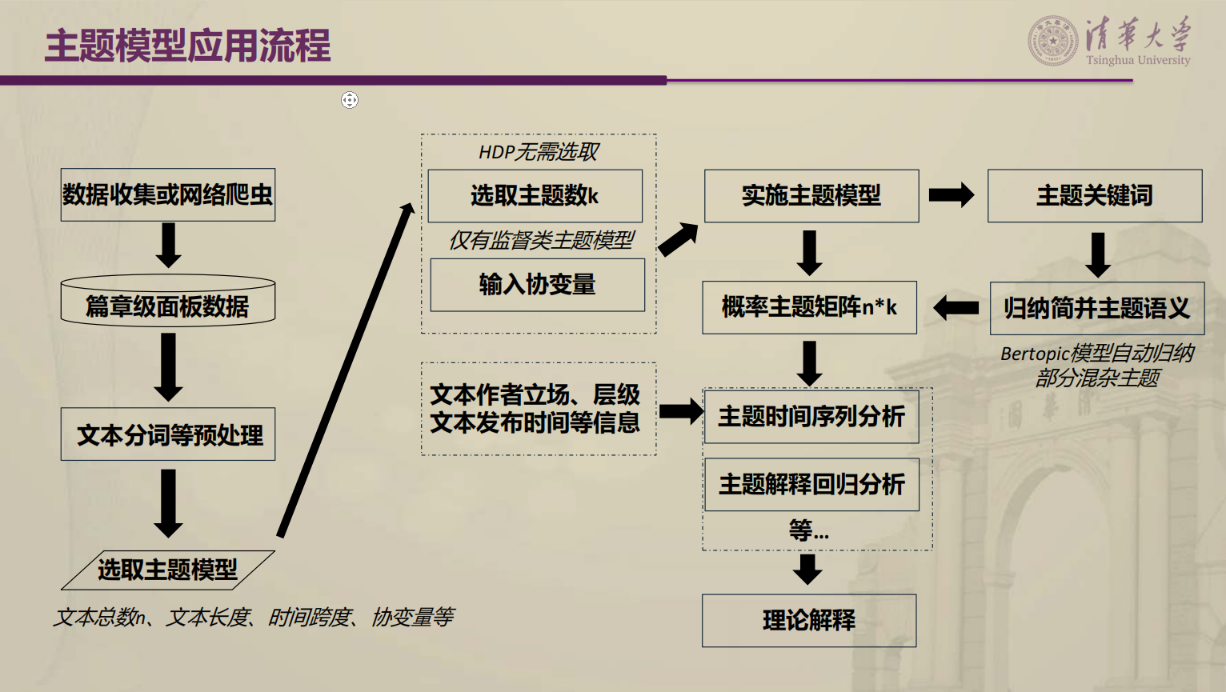
在以上基础上,张老师指出自动文本分析技术的发展助推了政府网站数据的应用研究,为大家介绍了不同种类的主题模型自动编码,同时重点分析了隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)主题建模的优势和操作过程。LDA作为从文本中提取主题的无监督学习算法,其优点是无需了解分析文本的先验知识,也避免了手工编码的任意性,还能够对“一词多义”和“一义多词”的语言现象进行建模。对于如何判断最优主题数,张老师给出三个解决办法:一是基于经验判断,二是基于平均困惑度判断,三是基于一致性度量。而后 张老师介绍了Bertopic主题模型分析的优点和应用,其优点在于根据数据实际分布动态调整主题数量,捕捉词汇间的关联性以及不同文档之间的语义关联,在高维空间中较好识别短文本的主题,并具有动态主题建模的能力。这些有效弥补LDA主题模型所面临的预设主题数量、文档和词汇的独立性假设、对短文本处理能力一般、缺乏时间动态演变特征等不足。
类型性测度作为关键变量的重要形式,这正是分类所要解决的问题,即将一个事件或者对象划分到给定的类别上。张老师从有监督机器学习的分类问题出发,介绍了有监督机器学习的分类过程和常见算法。分类器建构和使用分类器进行预测是两种主要分类过程,常见的算法包含决策树、随机森林算法、梯度提升决策树、最近邻分类、支持向量机、神经网络、朴素贝叶斯等,这些算法适用性不同的场景。在此基础上,张老师围绕组织声誉的一项研究,通过视频演示了随机森林算法的分类过程,深度剖析了类型性测度构建的应用思路。

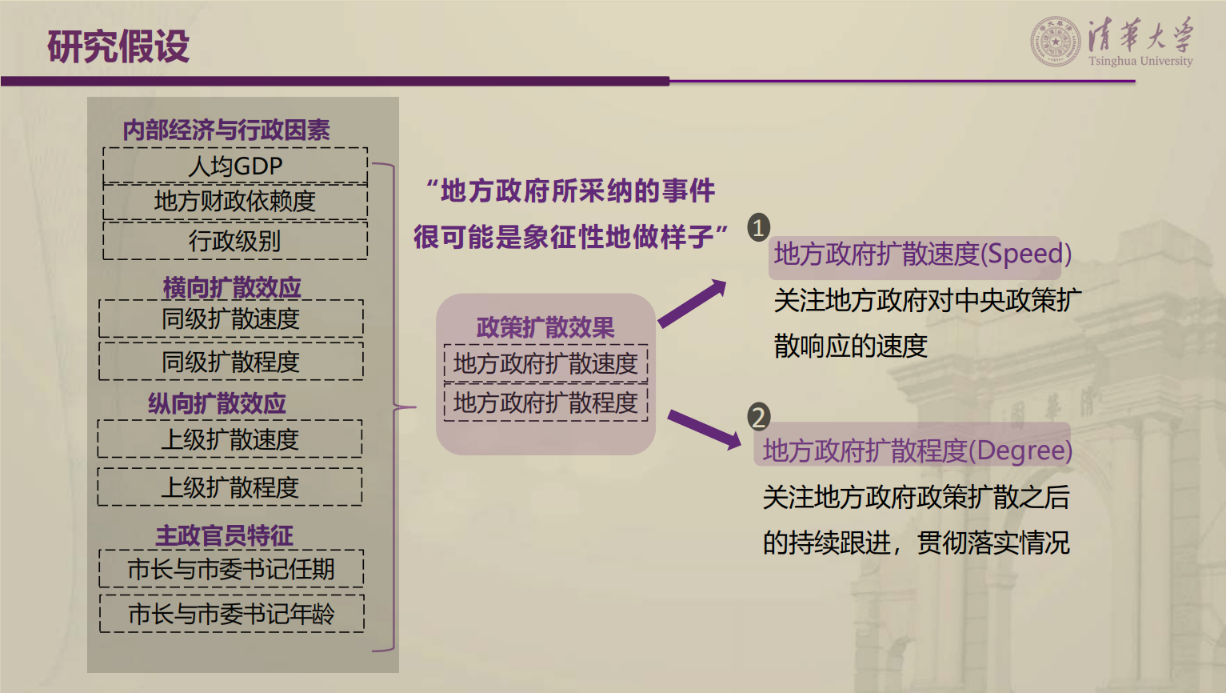
解释性测度作为关键变量的另一重要形式,张老师认为,政府网站内容数据不仅可以全景刻画政策注意力分配差异,而且为多主题层级政策扩散效果评估带来新的机遇,助推因果推断和知识发现。张老师使用其2023年发表于《管理科学学报》上的论文《全国政府网站内容数据中的知识发现:从注意力分配到政策层级扩散》作为例子,为学员详细讲解解释性测度构建的过程。研究中张老师构建了“政策扩散速度”和“政策扩散程度”两个中央政策层级扩散测度指标,评估了多主题层级政策扩散效果,并分析了影响短周期政策层级扩散的因素,为理解中央政策层级扩散现象提供了新角度。
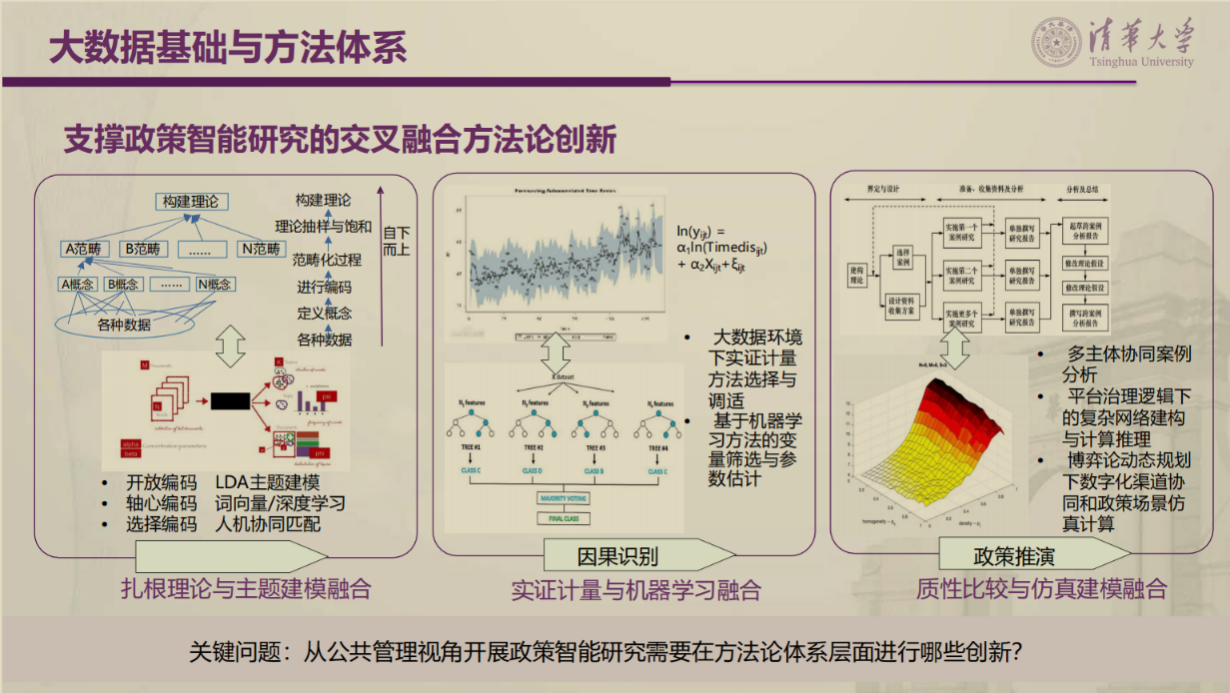
最后,张老师指出,政策信息学正在经历由内部数据分析到大数据挖掘,再到人工智能驱动的政策智能阶段。政策信息学要从面向跨学科的知识体系建构,走向面向政策决策中的科学前沿探索。当前政策智能的发展还处于萌芽阶段,政策智能研究面临环境要素复杂性、计算复杂性、认知行为复杂性和任务目标复杂性等多重挑战。未来从公共管理视角开展政策智能研究需要与场景充分融合,推动交叉融合方法论创新,如扎根理论与主题建模融合、实证计量与机器学习融合、质性比较与仿真建模融合。
撰稿人
中国人民大学 博士生 张迎新
浙江大学 博士生 柳鲲鹏
中共中央党校(国家行政学院) 博士生 陈晔


