2023年11月11日,由清华大学计算社会科学与国家治理实验室主办的清华交叉学科研究能力提升计划“大数据与因果推断研讨班”第六期在线上举行。厦门大学公共事务学院院长于文轩博士应邀作为主讲人,为逾2000名在线参会者做了主旨为《公共管理研究中的HLM模型》的讲座。讲座全程由清华大学公共管理学院陈思丞副教授主持。
于文轩老师首先介绍了生物学、经济学、统计学领域对具有嵌套型结构数据分析的方法,在管理学、社会学和教育学中一般使用HLM(Hierarchical Linear Models)。于老师从理论与统计分析方面的原因解释了为什么要使用HLM模型,其指出在理论上存在生态谬误和原子谬误,在统计分析上嵌套数据之间的属性并不完全一样,因此需要通过HLM模型对上述问题进行解决。相较于传统处理结构层次数据的方法,目前有如HLM、MLxor、MlwiN、SAS Proc Mixed、Stata、R等软件能够进行HLM分析。
于老师以发表在Journal of Public Administration Research and Theory上的文章“Means and ends: A comparative study of empirical methods for investigating governance and performance”举例,让同学们对公共管理领域相关实证研究有了一定了解。
于老师指出,HLM模型有两层,其中个体对整体均值的背离,代表个体差异,具有第一层方差;个体对自身均值的背离,是第二层方差。他用学生经济地位对其学习成绩的影响举例,在传统做法中,通常将学校的学生放在一起跑回归。此处暗含的假设是,这个学校里的学生的社会经济地位对考试成绩的影响的截距和斜率是一样的,即将其视为等同。然而,此处存在一个问题:在绝大多数情况下,这些截距和斜率其实不同。一个学校里的学生高度相关,另外一个学校里的学生也高度相关,不同地区如东南地区和西南地区的学生也各自在所属地区具有各自的相关性。如果用传统的方法把两个学校、两个地区的学生放在一起跑这个回归,显然会得出错误的结论。HLM能够解决上述问题,其将基层线性模型可以在第二个层面来看影响因素,如学校的情况如何影响这些学生的表现。
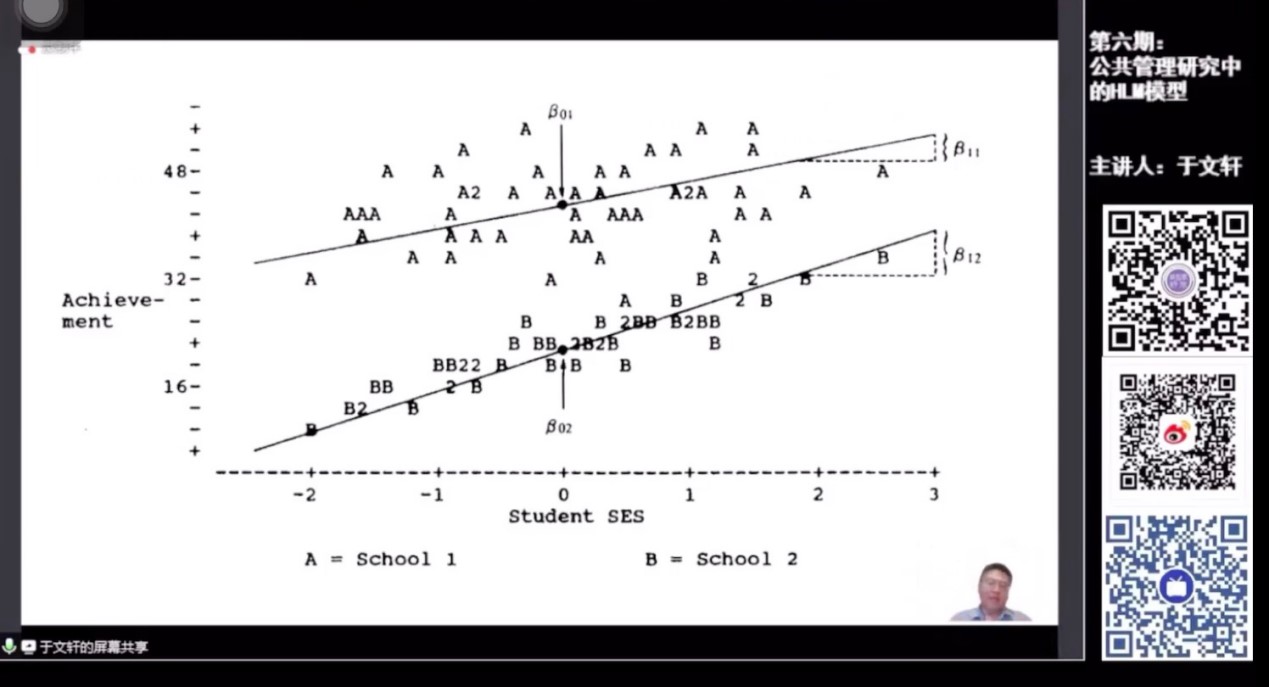
老师为了区分A Model with Nonrandom Varying Slopes与其他模型的区别,向学生生动了举了一个例子:假设level1为学生,level2为学校,该模型中学校和学生的个体属性不交互,如,学校的大门朝东西和学生的属性并无关系。同时指出该模型也可以发展成四层五层等,但是从理论和实践上讲都不具有科学性,此外在研究中一般多个X和W,是个矩阵或者向量,所以常用的为二层。
老师为了加深学生对模型的理解,向学生介绍了在该领域最具代表性研究之一“Exploring and Explaining Contracting Out Patterns among the American Sates”
该文章研究了美国各州政府公共服务外包活动,在研究中涉及两个问题,即各州政府在什么程度采用外包服务,外包对服务的成本和质量产生什么影响。影响政府外包服务的因素是什么。所以level1时是外包机构的变量,Level2是各州政府的变量。在这部分老师通过使用人工智能读取文章并汇总成笔记向同学们展示了人工智能的发展,并建议大家灵活和科学的使用人工智能。
在使用HLM模型中涉及多层,那么城市级别的数据如何影响个体数据?在此,老师向学生们推荐了书籍《Building Service-Oriented Government》。
在学习HLM模型后,老师向学生展示如何评估HLM模型的应用,即:
1. 是否使用稳健标准误等(满足样本条件且使用REML/ML)
2. 是否主要到样本筛选的随机性
3. 是否考虑0模型
4. 是否列出详尽公式
5. 是否给出估计办法
老师进一步指出,不要因为方法而方法,并结合文章”Conduting and Evaluating Multilevel Studies: Recomommendations, Resources, and a Checklist”说明了在使用HLM模型中需要注意的事项,即在使用方法时要有充分理论构建意义,要把每个层面的研究假设做出说明(random/ fix ),同时需要对level 1 中心化,在文章中报告样本量以及用什么方法进行拟合的。
在课程的结尾,考虑到学生基础的差异性,推荐了两本书籍《Multilevel Modeling in Plain Language》-(计量基础薄弱的学者)、《Hierarchical Linear Models》—(有计量基础的学者)。


