张楠:政府网站内容中的知识发现
2022年12月7日晚上,由清华大学计算社会科学与国家治理实验室主办的首届清华交叉学科研究能力提升计划“大数据与因果推断研讨班”第七讲在线上举行。本次讲座邀请清华大学公共管理学院教授张楠为研讨班学员作题为“政府网站内容中的知识发现”的主题讲座。本讲由清华大学公共管理学院副教授陈思丞主持,“大数据与因果推断研讨班”全体入选学员及助教以网络会议形式参加。
本次讲座以“政府网站内容中的知识发现”为主题。张楠老师介绍了本次讲座的主要内容与整体思路,围绕有关研究的心路历程,探讨在政府网站公开数据的驱动下如何做好研究,文本挖掘如何更有效地与计量方法、经典理论相结合,不同研究阶段如何理解政策信息学等问题,希望能够引起同学们、学者们对方法论以及方法论与具体研究间关系的思考。
(1)政府网站:各级政府言行的公开数据。2014年以来,随着国务院对政府网站的规范管理不断深入,加之各级政府网站内容数据的不断丰富和有效积累,为开展数据驱动的知识发现和管理决策研究汇聚了必要数据要素,也为动态监测各级政府对中央政策部署落实情况奠定基础。国内外越来越多的学者基于政府网站数据研究政府行为。本研究基于全国几十个节点部署近百台服务器,对2018年全国3万余家政府网站的400万政府网站栏目进行实时监测,获取246个地级市及副省级城市与28个省1,708,735条政府网站每日更新数据。
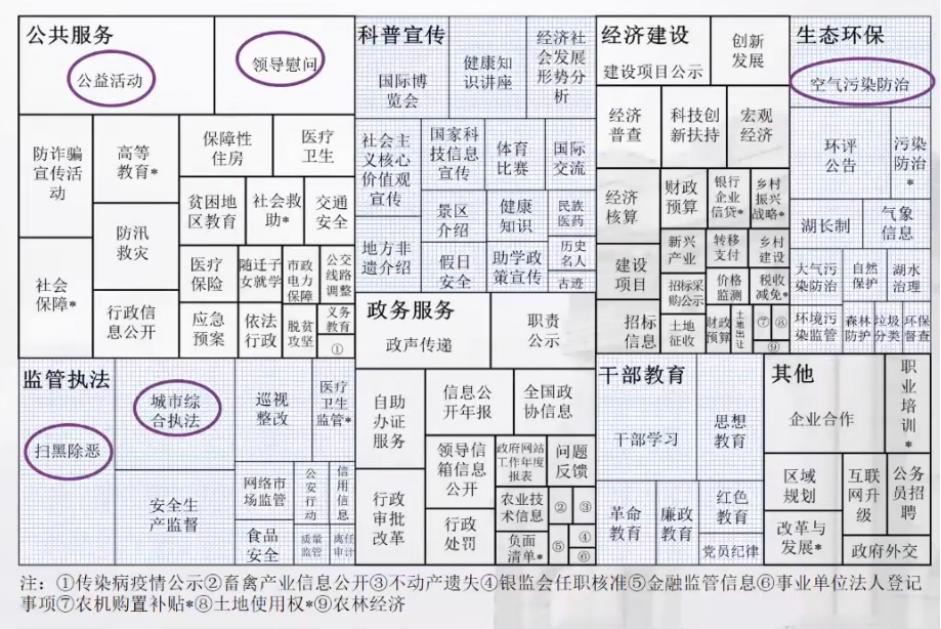
(2)注意力分布描述:概率主题建模。张楠老师讲述了LDA概率主题建模原理、应用、优点、操作过程等,强调了LDA建模中文档主题确定与文档主题概率矩阵确定步骤,提出了最优主题数判断方法,讨论了LDA的适用性问题;阐述了2018年政府网站对不同主题的注意力分配情况,使用120作为最优主题数对1,708,735条政府门户网页文本数据进行LDA主题建模,然后依次对建模得到的120个政策主题含义进行判断。可解释的政策主题数为112个,下图为主题含义和概率占比情况(即图中面积大小),反映了地方政府门户网站2018年的注意力分布情况;并介绍了其他相关研究示例。
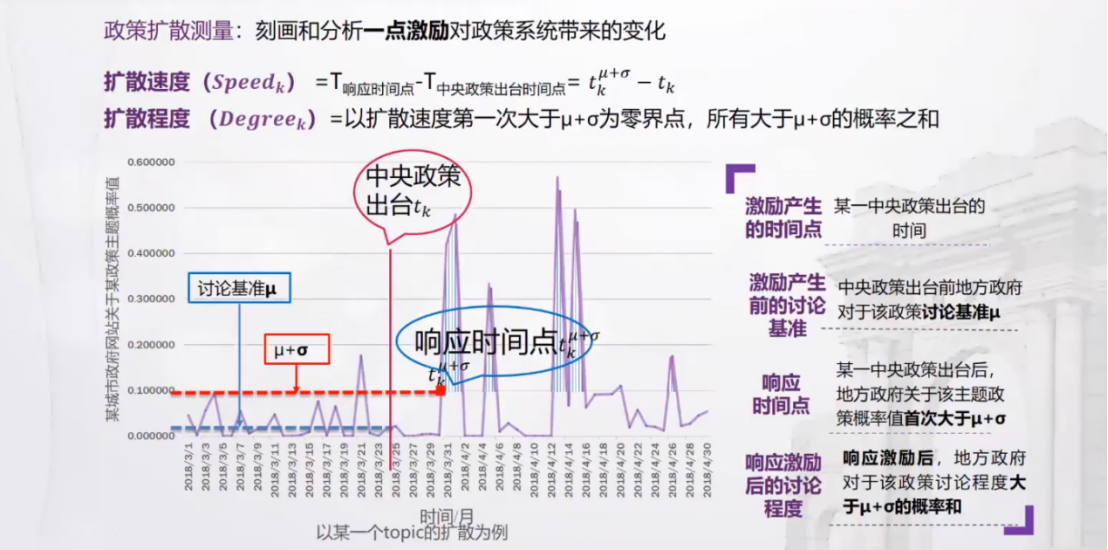
(3)管理意义测量:关键变量构建。传统的政策扩散测量方式面临挑战,标志性事件落地事件变得越来越难以明确,大数据视角下政策扩散测度应如何构建?基于下图所示测量方法,筛选出13个与中央政策高度对应的LDA建模主题,通过聚焦关键主题确保分析精度。基于研究结果,张楠老师展示了区域结果可视化、不同政策主题扩散速度百分位图等,并介绍了与相关研究示例的区别。
(4)理论假设检验:经典计量方法。本研究对话经典政策扩散模型,考虑中国特有的干部制度,做了两个方面的拓展,一是考量长周期政策扩散与短周期政策扩散,二是考量政策扩散的速度与程度。从测量结果来看,外部扩散机制在扩散程度中仍发挥作用,内部经济与行政因素中,仅各地人均经济水平对扩散速度和扩散程度具有显著影响。同时,对经济与行政因素、扩散速度、扩散程度、领导人特征等显著性进行了讨论,并介绍了相关研究示例。
(5)稳健性分析:有监督学习引入。为了验证因变量测量的稳健性,确保后续结果解释的有效性,研究也引入有监督学习思路,采用机器学习分类算法作为替代方法,重新计算每个城市响应中央政策主题的扩散速度和扩散程度,并作为新的因变量纳入回归模型。具体过程为:算法选择→主题选择→人工标注与机器学习分类(随机抽取该主题相关的1%网页文本数据进行人工标注所属类别,标注数据作为训练人工标注与机器集,对剩下的网页文本进行自动标注,计算出每个政府网页文本与选择题的相关类别)→因变量计算及回归分析。张楠老师还介绍了其他常见的稳健性检验方法、有监督的机器学习方法、常见算法比较与相关研究示例等。
(6)未来展望:从政策信息学到政策智能。政策智能:以政策信息学为基础,将人工智能技术体系化地嵌入政策制定、分析、实施、反馈流程中,采用更加主动、全面的视角,面向未来可能发生的场景和情境进行积极的推演预测和前瞻性分析。目前政策智能发展处于萌芽阶段,政策智能研究面临着技术挑战,政策智能需要管理场景与视角。
张楠老师就学员的提问作出了详细解答,对有关研究方法应用进行了指导。陈思丞老师向张楠老师的精彩授课表示感谢并进行总结。至此,本次讲座圆满结束。


